
Exploring curation micro-services
 As far as I’m concerned, the most exciting developments this year in repositories and digital curation have come out of the California Digital Library. It has been impossible not to notice their papers and presentations. Put simply, their idea is that digital curation is enabled by “micro-services” built upon well-known abstractions such as the filesystem. The benefits are obvious: filesystem tools are ubiquitous and cross-platform, and there are strong market forces to ensure the filesystem persists. The idea is radically simple and straightforward, though many questions remain about such a paradigm. I’ll return to those later.
As far as I’m concerned, the most exciting developments this year in repositories and digital curation have come out of the California Digital Library. It has been impossible not to notice their papers and presentations. Put simply, their idea is that digital curation is enabled by “micro-services” built upon well-known abstractions such as the filesystem. The benefits are obvious: filesystem tools are ubiquitous and cross-platform, and there are strong market forces to ensure the filesystem persists. The idea is radically simple and straightforward, though many questions remain about such a paradigm. I’ll return to those later.
If you have not yet taken a look at CDL’s curation micro-service specifications, most of which may be printed on as few as one or two sheets of paper, see the Digital Library Building Blocks.
My co-workers in the LC Repository Development Center have been chatting about these specs on and off throughout the year. After months of procrastinating, I finally read all of the specs on Thursday; it’s wonderful that you can do so in the course of one reading session, I might add. Yesterday a bunch of us RDCers got together to chat (informally) about the specs: what they’re for, how they work, and how they interact with one another. I learn by doing, by examples, so I combed through each of the specs in advance of our meeting and tried to construct a minimal repository1 based on micro-services.
Here is a tree visualization of the final product, inevitable warts and all: 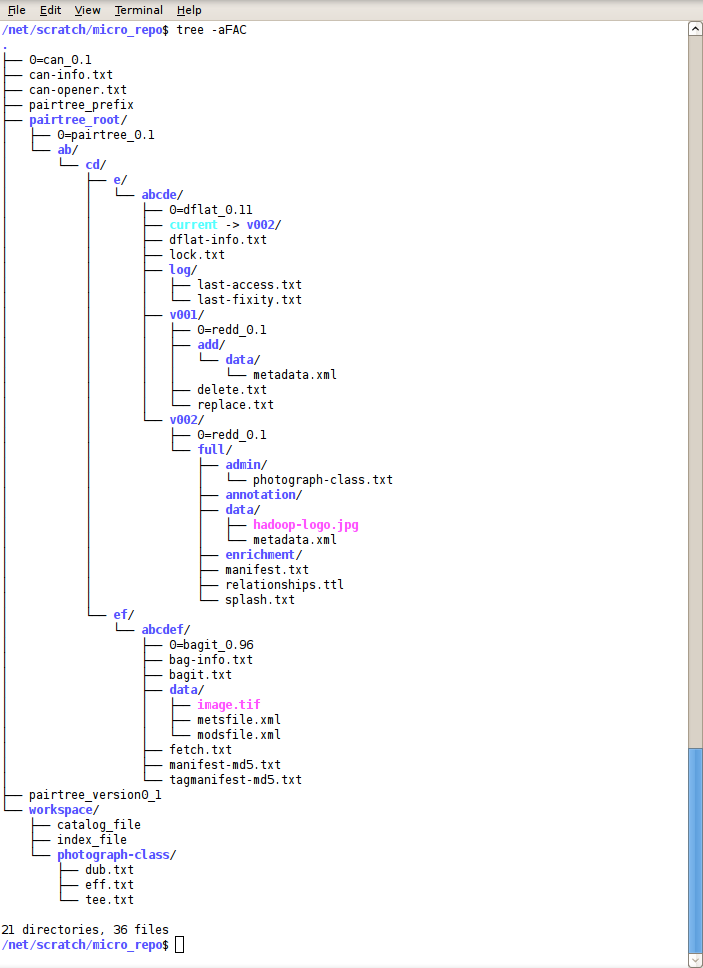 The services I used were Namaste, Content Access Node (CAN), Pairtree, Dflat, Reverse Directory Deltas (ReDD), Class-based System for Managing Object Properties (CLOP), and BagIt (co-developed by LC and CDL).
The services I used were Namaste, Content Access Node (CAN), Pairtree, Dflat, Reverse Directory Deltas (ReDD), Class-based System for Managing Object Properties (CLOP), and BagIt (co-developed by LC and CDL).
As I mentioned in our Friday meeting, recounting my experience exploring the specs: the bad thing is that I spent an hour building a repository with rudimentary tools such as mkdir, touch, cp, ln, and emacs; but the good thing is that I built a repository in one hour using common, rudimentary tools. It’s a very compelling paradigm. Ed’s already built a tool implementing some of Dflat, further demonstrating how lightweight these micro-services are. (UPDATE: Ed notes that this code is a work in progress and is “barely functional.”) (UPDATE 2: The dflat library has come a long way. Check it out if you’re interested. Also, I just committed a pretty basic Namaste library: http://github.com/mjgiarlo/namaste. Only took about an hour, which is a testament to the power of lightweight specs.)
I am certain this will be a running thread at work as the specifications evolve and our understanding of them grows. Some questions and comments that occurred to me while exploring the micro-service specs and building the minimal repo:
- CAN was a bit puzzling. The spec is simple enough, but I found some of the conventions confusing, and I was left wondering what CAN provides other than a container. What I would like to see is a simple use case and perhaps more examples. Thus, the CAN stuff in my sample repo doesn't feel very useful only because I had a hard time working with the spec.
- CLOP feels like the least mature of the specifications. It seems generally useful to be able to put digital objects, however you define that, into classes and define properties on those classes. The spec did not clearly convey to me just how it accomplishes that aim. A few examples would go a very long way. I've got some CLOP stuff in the sample repo but I have no idea how close my implementation matches the spec.
- Is Dflat dependent on ReDD? One would assume not since there's an optional property in the dflat-info.txt file for specifying a delta scheme. But, say, could you stub out the v001 directory (reserved to hold the initial version of a digital object) and use a system such as git or bazaar?
One might argue that these established delta schemes, if you want to call them that, have many more developers and users than a system such as ReDD and thus should persist longer and have more tools built around them. I imagine the micro-service viewpoint would acknowledge that point, but counter that the spirit of these specs is to avoid dependencies from outside the filesystem? - Is the ReDD specification meaningful outside of a Dflat given that any one ReDD directory knows nothing of its successors and predecessors, or is it dependent upon Dflat?
- Could a BagIt bag live inside of the ReDD reserved "full" directory? That is, could the "full" directory be marked up appropriately to be a BagIt bag?
- How many tools exist for these specs? I notice there's code in CPAN for Pairtree and Namaste, which is a fabulous start. Tools are the difference between YAMF (Yet Another Messy Filesystem) and reliably managed curation services. Granted, tools such as cp and emacs already exist and are part of the appeal of these micro-services, but there's also tremendous room for error if operations are all done "by hand."
- To what extent has CDL transitioned to using these specs/tools?
- Are other institutions using these specs/tools? I have heard tell that digital library folks from the University of Michigan and the University of North Texas may be involved.
I hope I don’t sound overly critical. I’m really glad our colleagues at the California Digital Library have written these specifications and applied their deep experience to what could be a transformative paradigm2 in the digital curation world. Kudos to them!
-
Perhaps it’s more in line with the specs to refer to this space as “a managed filesystem that drives repository and curation services,” given the CDL philosophy that preservation is not a place/repository. But it’s easier to say “repository,” so there you go. ↩
-
Please excuse the fanboyishness; this filesystem fetishism is exciting stuff! ↩